Почему веб-сайт с заполнением ключевых слов занимает более высокое место, чем сайт без результатов поиска Google?
Как и некоторые другие веб-сайты, я стараюсь поддерживать баланс в ключевых словах по сравнению с другими словами. Я провел тесты своего (оптимизированного) веб-сайта, а также (заполненного ключевыми словами) веб-сайта-конкурента с помощью этого SEO-инструментов/анализатора ключевых слов.
Что еще более безумно, так это то, что точная фраза, которую люди ищут ("парень и 4-й"), содержит слово, которое поисковые системы игнорируют. Взгляните на результаты.
И...
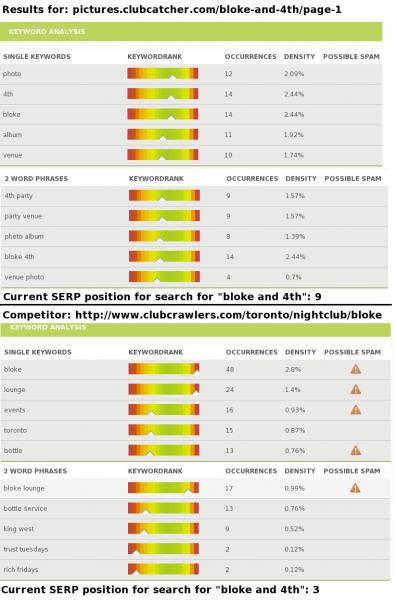
Как вы можете видите ли, на веб-сайте, который занимает более высокое место, есть возможные индикаторы спама, прикрепленные к нему, где, как и на моем сайте, их нет.
Так почему же один веб-сайт с большим количеством индикаторов спама может занимать более высокое место, чем веб-сайт без индикаторов спама? Действительно ли Google сейчас начинает продвигать наполнение ключевыми словами со всеми изменениями, которые они вносят на свои собственные страницы?
1 answers
Это очень просто. Плотность ключевых слов - это своего рода миф. По крайней мере, сейчас это так.
Важно отметить, как используются термины, а не сколько раз они используются. Оптимизаторы любят намеренно запутывать проблему, чтобы держать вас в зависимости от них и платить за инструменты и советы. П.Т.Барнум говорил, что каждую минуту рождается неудачник. В SEO второстепенным событием, похоже, являются все онлайн-советы. Что еще печальнее, оптимизаторы движутся медленнее, чем PageRank, который гораздо медленнее, чем трава, растущая в Сахаре. Они не так легко отходят от старых концепций, даже если с самого начала были совершенно неправы.
Это мини-учебник о том, как взвешиваются термины на сайте. Это ни в коем случае не полное объяснение, а иллюстрация. Это стоящее путешествие, чтобы лучше понять, как работает SEO.
До взвешивания терминов и тем сайта с использованием семантики взвешивание ключевых слов проводилось с использованием нескольких показателей, включая использование и размещение терминов в тегах, таких как теги title, теги заголовков, мета-теги description, а также близость друг к другу и важные теги и другие указания на важность и т.д. Частью указания на важность было использование терминов, синонимов, дополнительных терминов и то, насколько заметными казались эти термины. Это несколько соответствует понятию плотности ключевых слов, и, пожалуйста, знайте, что для определения темы страницы применялись соотношения терминов, однако это были не высокие или низкие соотношения терминов, а соотношение, которое эффективно удаляйте общие термины, повторяющиеся термины, неестественное использование терминов и термины, которые просто не имеют ценности из-за отсутствия использования и т.д. Эти соотношения терминов были автоматически оценены постранично, и результаты совпали с расчетами, которые определяют, соответствуют ли результаты операционной области. Когда все было сказано и сделано, термины действительно определяли тему и объем темы, используя семантику, описанную позже. Но плотность не имела никакого отношения к рангу поиска как таковому, а скорее к теме и соответствие цели поиска. Вторичный эффект заключается в совпадении терминов определенной плотности по случайности, поскольку одни и те же термины соответствуют профилю, определяемому с помощью семантических ссылок, и использовались для определения цели поиска. Это последовало за моделью синтаксического анализатора, которая частично все еще существует, но не является полной моделью. Больше нет.
Семантика сегодня является основной моделью, хотя, поскольку веб следует традиционной текстовой модели, модель синтаксического анализатора не может быть полностью отброшена. Причина этого заключается в простой. Это все еще применимо, имеет смысл и очень полезно.
Семантику можно описать как "реляционное сопряжение", хотя для некоторых более сложных семантических моделей вы действительно говорите о "реляционных цепочках". Это известно как семантические связи, а связь между семантическими связями известна как семантическая сеть, которая не имеет ничего общего со всемирной паутиной, за исключением того, что одна удобна для другой. Для иллюстрации я ограничусь простыми парами хотя семантика довольно быстро усложняется. Поэтому для моей иллюстрации я буду немного упрощать вещи.
Реляционное сопряжение - это простое понятие тройки: субъект, предикат и объект. Предикатом может быть что угодно, если он является репрезентативным между субъектом и объектом.
Я отклонюсь от ранней модели PageRank. Пожалуйста, оставайся со мной. Это применимо.
Когда был задуман Google, понятие ранга страницы было довольно простое представление сетей доверия с использованием семантики. Ссылка делается с одной страницы на другую. В этом случае:
Subject: examplea.com
Predicate: trusts
Object: exampleb.com
Read as: examplea.com trusts exampleb.com
Subject: exampleb.com
Predicate: trusts
Object: examplec.com
Read as: exampleb.com trusts examplec.com therfore examplea.com trusts examplec.com
Хотя мы знаем, что приведенное выше предложение "следовательно" не обязательно верно, это была ранняя модель, и она все еще в некоторой степени верна, хотя и не совсем верна. Мы знаем, что examplea.com может не знать о examplec.com и поэтому не может полностью доверять examplec.com . Тем не менее, существует связь, которую необходимо учитывать.
Раннее использование термин PageRank был рассчитан на основе страницы по ссылке, но применялся ко всему сайту. Для exampleb.com , сколько существует доверительных связей? PageRank представлял собой довольно простой расчет ссылок на страницы сайта. Но с этим были очевидные проблемы. Ссылки могут быть сделаны для искусственного завышения важности сайта. Расчет содержал довольно стандартную скорость распада, которая могла бы исправить это, однако скорость распада сама по себе создавала новые проблемы в том, что ни один распад ставка может полностью учитывать фактическое значение, поскольку ее естественная склонность заключается в том, чтобы иметь кривую в ее расчете.
При дальнейшем использовании модели доверия домены были взвешены на основе факторов, указывающих на доверие. Например, самым большим показателем доверия является возраст сайта. Старым сайтам, как правило, можно доверять. Сайты с постоянной регистрацией, постоянным IP-адресом, качественным регистратором, качественной сетью (хостом), не имеют истории спама, порнографии, фишинга и т.д. все указывает на доверие. Я считаю до конца 50 факторов доверия к домену, поэтому я пропущу их и продолжу упрощать.
Subject: examplea.com
Predicate: domain trust score
Object: 67
Subject: exampleb.com
Predicate: domain trust score
Object: 54
Subject: examplea.com
Predicate: trusts
Object: exampleb.com
Read as: examplea.com trusts exampleb.com
Используя другой расчет, можно установить некоторый уровень доверия, а не просто двоичный , один сайт доверяет другому . Если в первом примере передавалось доверие, то во втором примере значение доверия передается пропорционально тому, как оно рассчитывается.
Теперь, пожалуйста, поймите, что PageRank рассчитывается постранично, и TrustRank - это большая часть SiteRank, ссылки на которую, качество ссылок, ценность ссылок играет определенную роль, хотя и гораздо менее важную, чем изначально, и гораздо меньшую, чем оценка доверия к сайту. Имейте это в виду.
Как это относится к ключевым словам на странице??
Все термины контента взвешены, однако взвешены только некоторые термины тегов. Одним из основных примеров является мета-тег keywords. Мы все знаем, что термины в этом теге вообще не имеют веса. На самом деле, это полностью игнорируется. Одно из заблуждений заключается в том, что мета-тег description не учитывается при SEO. Это неправда. Для терминов в этом теге есть вес, однако он относительно невелик. Мета-тег описания действительно имеет значение. Немного позже вы поймете, почему.
Старая модель синтаксического анализатора все еще имеет ценность. При этом страница читается сверху вниз, а теги и блоки содержимого считываются и взвешиваются с использованием значений, которые оценивают важность в соответствии с моделью сверху вниз. Некоторые показатели являются статическими. Например, тег title будет иметь оценку важности выше, чем тег h1, который будет выше чем любой тег h2 и т.д. Мета-тег description будет иметь довольно высокий показатель важности. Почему? Потому что это все еще важный показатель того, о чем идет речь на странице. Однако термины, содержащиеся в теге, имеют небольшой вес. Это сделано для того, чтобы совпадения с целью поиска по-прежнему соответствовали метатегу description почти так же легко, как тегу title и тегу h1, но ими нельзя манипулировать слишком сильно, чтобы играть в систему. Пожалуйста, обратите внимание, что могут применяться определенные условия. Например, поиск будет не совпадает с метатегом description без сопоставления в других местах, в первую очередь с тегом title или тегом h1 или внутри содержимого.
Продолжая работу с моделью синтаксического анализатора, представьте точку в начале фактического содержимого. Близость - это мера, которая используется различными способами. Один из них заключается в том, что термин, тег, блок содержимого и т. Д. Относятся к этой точке в начале содержимого. Теперь подумайте о тегах заголовков как указателях подтем и представьте точку в начале содержимого сразу после тега заголовка, завершающегося следующим тегом заголовка. Снова измеряется близость. Близость измеряется между терминами в абзаце, наборами абзацев, тегами header и т.д. Эти показатели рассчитываются как вес для терминов в том, как они используются, и их очевидная важность. Выходя за рамки этого, термины, фразы, цитаты и, действительно, любая аналогичная часть контента могут быть измерены между страницами и сайтами, используя несколько иную, но все же схожую близость модель.
Страницы связаны ссылками как со страницы на страницу, так и по близости с домашней страницы или любой другой страницы, на которой можно определить облако отношений. Например, страница темы по SEO может содержать ссылки на несколько страниц подтемы SEO. Это означало бы, что страница темы для SEO важна тем, что она ссылается на несколько похожих тематических страниц, и можно определить облако отношений. Таким образом, для любой страницы подтемы SEO близость будет подсчетом ссылок между SEO страница темы и страница подтемы SEO, а также количество ссылок с домашней страницы. В этом случае можно рассчитать важность страниц. Насколько важна страница темы SEO? Это одна ссылка из навигационных ссылок на главной странице, и действительно, каждая страница - очень важная. Однако страницы подтемы SEO не содержат ссылок из навигации и, следовательно, получают какое-либо значение от показателя для страницы темы SEO. Это соответствует модели сети доверия семантическим ссылкам PageRank.
Возвращаясь к в оригинальной модели PageRank вы можете оценивать страницы по тому, как вы на них ссылаетесь, точно так же, как ссылки передают ценность во всемирной паутине. Это называется скульптурой, хотя чрезмерная манипулятивная скульптура может быть определена и проигнорирована, поэтому будьте естественны. Делая это, вы также указываете на важность терминов, содержащихся на этих страницах. Таким образом, любой термин на любой странице зависит не только от того, где и как они используются на этой странице, но и от очевидной важности страницы в том, как и где она существует на ваш сайт. Это начинает обретать смысл?
Хорошо. Хорошо и хорошо, но как связаны термины и как семантика помогает в этом? Опять же, все очень просто.
У меня есть сайт об автомобилях. Вы находитесь в Великобритании, и у вас есть сайт об автомобилях. Довольно очевидно, что автомобили и автомобили - это одно и то же слово. Поисковые системы используют словарь, чтобы лучше понять взаимосвязи между словами и темами. Google дифференцировал себя, создав самообучающийся словарь на ранней стадии на. Я не буду вдаваться в это, но вы все равно получите представление. Использование семантики:
Subject: cars
Predicate: equals
Object: automobiles
В этом случае Google может понять, что мой сайт и ваш сайт - это примерно одно и то же. Делая еще один шаг вперед.
Subject: car
Predicate: is painted
Object: dark red
Subject: automobile
Predicate: is painted
Object: maroon
Subject: deep red
Predicate: equals
Object: maroon
Предположив на мгновение, что существуют только эти два сайта, любой поиск темно-красного автомобиля может привести к темно-бордовому автомобилю и темно-красному автомобилю, даже если темно-красного автомобиля не существует в Интернете.
В в первые дни SEO было рекомендовано использовать синонимы и варианты терминов во множественном числе. Это было в те времена, когда семантика не использовалась или была такой сильной. Сегодня вы можете видеть, что в этом нет необходимости, так как отношения между словами и их использованием хранятся в базе данных семантики.
Используя ту же модель, но немного забегая вперед, если я напишу блестящую статью, которая цитируется на нескольких других веб-страницах, семантика может отметить это как цитату и отнести это к моей оригинальной работе, дающей ее гораздо важнее даже без ссылок на мою страницу вообще. В этом случае страница без входящих (обратных) ссылок может превзойти страницу с большим количеством входящих (обратных) ссылок просто из-за цитаты. Цитаты являются важной частью применения семантической сети во всемирной паутине. На самом деле, пока СЕО гонялись за аллюзив-ным авторским рейтингом, такого понятия не существовало. Это была вся семантика и сопоставление пар данных , в которые я не буду вдаваться, но скажу, что, например, написано может сразу же указать имя автора, и, следовательно, к автору может быть применен кредит на цитирование, если статья была процитирована.
Зачем я прошел через все это??
Так что вам будет легко увидеть, что механизм оценки любого термина на сайте намного сложнее и больше не зависит от плотности, которая в любом случае никогда не была полной. На самом деле плотность больше не является вторичным эффектом вообще. Причина этого проста. В нее было легко играть и никакого распада скорость может компенсировать игру, как и в оригинальной схеме PageRank.
Что касается любого сайта, наполненного ключевыми словами, то это только вопрос времени, когда семантика выдаст их. Panda начиналась как периодическая задача, которая была разработана специально для измерения этого и других подобных вещей и корректировки показателей, чтобы снизить влияние сайта-нарушителя в поисковой выдаче. В то время как рейтинг сайта, как правило, остается неизменным, любой сайт, обнаруженный в спаме, получит удар по рейтингу доверия, имея имел нарушение, таким образом, слегка понизив рейтинг сайта. Я считаю, что в этом механизме есть компонент строгости, который позволяет исправлять мелкие правонарушения без вреда для себя. Этот стук остается даже тогда, когда проблема решена. Это происходит потому, что нарушение сохраняется в истории сайтов. Итак, что происходит, так это то, что размещение SERP будет снижаться до тех пор, пока не будет решена проблема, при которой размещение SERP снова начнет расти, но никогда не достигнет уровня, который когда-то был у сайта-нарушителя из-за запись о нарушении. Чем старше становится нарушение, тем больше оно прощается, позволяя предыдущему правонарушению со временем утратить свой негативный эффект. В качестве примечания, хотя говорят, что Panda и другие запускаются чаще, и сегодня это непрерывный процесс, все равно требуется время, чтобы построить карту семантических ссылок, чтобы узнать, является ли сайт нарушителем. Это означает, что сайт какое-то время будет обходиться без наполнения, но в конце концов потерпит неудачу, как только семантические ссылки и показатели будут полностью установлены. Кроме того, я конечно, есть первоначальный эффект для начинки, но он значительно уменьшается при использовании семантической модели, и эффект довольно поверхностный как побочный продукт. Это связано с тем, что при обнаружении страницы мало что можно сделать, пока не будут заполнены карты семантических ссылок. Google, в своей мудрости, допускает некоторую милость, что позволяет странице занимать высокое место по терминам в важных сигналах изначально, прежде чем перейти к правильному размещению в поисковой выдаче. Предполагая, что сигналы соответствуют семантике, затем пересчет размещения SERP приведет к относительному сдвигу в способе поиска страницы. В противном случае, если сигналы и семантика не совпадают, размещение в SERP будет основано на семантике, и способ нахождения страницы изменится. Вот почему важно в первую очередь посылать правильные сигналы, используя ключевые слова и теги точно и честно.
[Обновление]
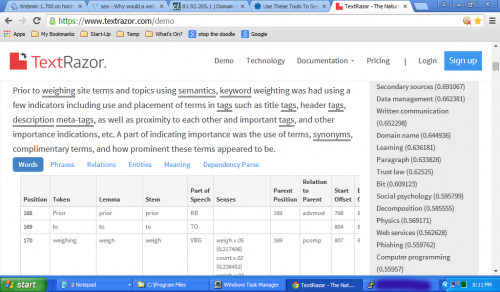
Я вырезал и вставил этот ответ в TextRazor https://www.textrazor.com/demo и вот вам пример. Вы увидите относительное положение к этой воображаемой точке в начале анализа содержания и других лингвистических исследований в таблице, а также оценки по теме справа. Вы можете сделать то же самое, вырезав текст этого ответа (выше этого обновления), вставив его на демонстрационную страницу и немного поиграв. Я поощряю это. Это даст вам хорошее представление о том, как обрабатывается контент.