Группировка данных запросов PHP Oracle
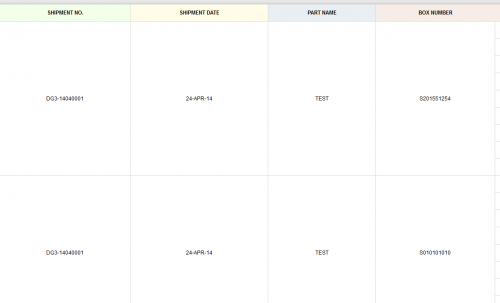
Мой дизайн данных запроса в таблице выглядит следующим образом:
SHIPMENT_NO SHIPMENT_DATE PART_NAME BOX_NUMBER
DG3-14040001 4/24/2014 TEST S201551254
DG3-14040001 4/24/2014 TEST S010101010
DG3-14040001 4/24/2014 TEST S100200123
DG2-14040001 4/24/2014 DG-M11-A S001545525
Чего я хотел, так это:
SHIPMENT_NO SHIPMENT_DATE PART_NAME BOX_NUMBER
DG3-14040001 4/24/2014 TEST S201551254
4/24/2014 TEST S010101010
4/24/2014 TEST S100200123
DG2-14040001 4/24/2014 DG-M11-A S001545525
Потому что отгрузка № DG3-14040001 такая же, поэтому она покажет только 1 значение.
А вот Мой Oracle SQL:
SELECT SHIPMENT_NO, SHIPMENT_DATE, PART_NAME, BOX_NUMBER FROM DIGI_SHIPMENT_SCAN WHERE TO_CHAR(SHIPMENT_DATE,'YYYY-MM-DD') BETWEEN '$start_date' AND '$end_date' GROUP BY SHIPMENT_NO, SHIPMENT_DATE, PART_NAME, BOX_NUMBER
while($d1 = oci_fetch_array($result_q1))
{
$shp_no = $d1['SHIPMENT_NO'];
$shp_date = $d1['SHIPMENT_DATE'];
$part_name = $d1['PART_NAME'];
$box_number = $d1['BOX_NUMBER'];
SELECT COUNT(*) AS TOTAL_SHP FROM DIGI_SHIPMENT_SCAN WHERE TO_CHAR(SHIPMENT_DATE,'YYYY-MM-DD') BETWEEN '$start_date' AND '$end_date' AND SHIPMENT_NO = '$shp_no'
$result_q3 = oci_parse($c1, $q3);
oci_execute($result_q3);
$d3 = oci_fetch_array($result_q3);
$total_shp = $d3['TOTAL_SHP'];
<td class="td_brd7 td_brd6" rowspan="<?php echo $total_shp; ?>"><?php echo $shp_no; ?></td>
<td class="td_brd7 td_brd6" rowspan="<?php echo $total_shp; ?>"><?php echo $shp_date; ?></td>
<td class="td_brd7 td_brd6" rowspan="<?php echo $total_shp; ?>"><?php echo $part_name; ?></td>
<td class="td_brd7 td_brd6" rowspan="<?php echo $total_shp; ?>"><?php echo $box_number; ?></td>
}
Когда появится результат, он покажет, что Двойная отгрузка Не зависит от запроса общей строки номера ЯЩИКА.
Вы можете видеть на картинке, номер отгрузки должен показывать значение 1, потому что одно и то же значение.
Пожалуйста, помогите советом.
3 answers
Такого рода форматирование действительно должно выполняться на уровне приложения, даже если это возможно в SQL. Удаление значения из строки таблицы делает результат больше не реляционным набором данных.
Вы можете сделать это с помощью LAG():
SELECT (CASE WHEN SHIPMENT_NO = LAG(SHIPMENT_NO) OVER (ORDER BY SHIPMENT_NO, SHIPMENT_DATE, PART_NAME, BOX_NUMBER) AND
SHIPMENT_DATE = LAG(SHIPMENT_DATE) OVER (ORDER BY SHIPMENT_NO, SHIPMENT_DATE, PART_NAME, BOX_NUMBER) AND
PART_NAME = LAG(PART_NAME) OVER (ORDER BY SHIPMENT_NO, SHIPMENT_DATE, PART_NAME, BOX_NUMBER)
THEN ''
ELSE SHIPMENT_NO
END) as SHIPMENT_NO,
DSS.SHIPMENT_DATE, DSS.PART_NAME, DSS.BOX_NUMBER
FROM DIGI_SHIPMENT_SCAN DSS
WHERE TO_CHAR(SHIPMENT_DATE,'YYYY-MM-DD') BETWEEN '$start_date' AND '$end_date'
GROUP BY DSS.SHIPMENT_NO, DSS.SHIPMENT_DATE, DSS.PART_NAME, DSS>BOX_NUMBER
ORDER BY DSS.SHIPMENT_NO, DSS.SHIPMENT_DATE, DSS.PART_NAME, DSS.BOX_NUMBER;
Для этого требуется разобраться с некоторыми тонкостями. Вывод должен быть явно упорядочен. Вы не можете зависеть от порядка результирующего набора, если не включите предложение order by. Затем вам нужно использовать тот же порядок для lag(), без предложения partition by.
Обратите внимание, что в запросе также используются псевдонимы таблиц. Это связано с тем, что псевдоним столбца SHIPMENT_NO можно спутать со столбцом DSS.SHIPMENT_NO в предложении order by. Вам нужно быть конкретным, иначе все пустые столбцы появятся вместе.
Обычно это следует делать в логике вашего приложения, но это также можно сделать с помощью разумного использования функции LAG().
ЛАГ() позволяет оценить предыдущую строку в соответствии с определенным порядком. Затем вы можете применить СЛУЧАЙ, когда для отображения значения NULL, когда оно совпадает с предыдущей строкой.
Http://docs.oracle.com/cd/B19306_01/server.102/b14200/functions070.htm
Пример:
SELECT CASE WHEN LAG(Shipment_No)
OVER (ORDER BY Shipment_No, Order_Date) = Shipment_NO
THEN NULL ELSE Shipment_No END AS Shipment_NO,
(...)
FROM YourTable
ORDER BY Shipment_No, Order_Date;
Как насчет использования break on?
break on SHIPMENT_NO;
SELECT SHIPMENT_NO, SHIPMENT_DATE, PART_NAME, BOX_NUMBER
FROM DIGI_SHIPMENT_SCAN WHERE
TO_CHAR(SHIPMENT_DATE,'YYYY-MM-DD')
BETWEEN '$start_date' AND '$end_date' GROUP BY
SHIPMENT_NO, SHIPMENT_DATE, PART_NAME, BOX_NUMBER
Http://docs.oracle.com/cd/B19306_01/server.102/b14357/ch6.htm
Подавление повторяющихся значений в столбцах разрыва
Команда BREAK по умолчанию подавляет повторяющиеся значения в названном вами столбце или выражении. Таким образом, чтобы подавить повторяющиеся значения в столбце, указанном в предложении ORDER BY, используйте команду BREAK в ее простейшей форме:
BREAK ON break_column
Примечание:
Всякий раз, когда вы указываете столбец или выражение в BREAK команда, используйте предложение ORDER BY, указывающее тот же столбец или выражение. Если вы этого не сделаете, разрывы будут происходить каждый раз при изменении значения столбца.
Пример 6-10 Подавление повторяющихся значений в столбце разрыва
Чтобы отключить отображение повторяющихся номеров отделов в показанных результатах запроса, введите следующие команды:
BREAK ON DEPARTMENT_ID;
Для следующего запроса (который является текущим запросом, хранящимся в буфере):
SELECT DEPARTMENT_ID, LAST_NAME, SALARY
FROM EMP_DETAILS_VIEW
WHERE SALARY > 12000
ORDER BY DEPARTMENT_ID;
DEPARTMENT_ID LAST_NAME
SALARY
------------- ------------------------- ----------
20 Hartstein 13000
80 Russell 14000
Partners 13500
90 King 24000
Kochhar 17000
De Haan 17000
6 rows selected.