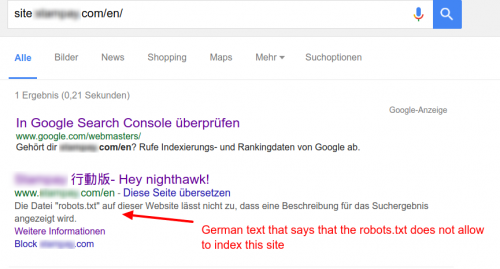
Страница заблокирована robots.txt отображение на сайте: результаты поиска с описанием, которое представляет собой смесь китайского, английского и немецкого языков
Я нашел странный результат поиска для ресурса, заблокированного robots.txt.
Почему там китайский (угаданный) текст, за которым следует текст Hello nighthawk!. Это эстерегг Google?
Вчера я попытался удалить URL-адрес из Google с помощью инструментов для веб-мастеров.
Там не было Hello Nighthawk!, только "заблокированный robots.txt - сообщение. Об этой проблеме сообщил один из соавторов.

Таково содержание robots.txt:
User-agent: *
Disallow: /en
Домены перенаправляются следующим образом:
www.domain.com/en -> (301) https://domain.com/en
Страница https://domain.com/en показывает обычную страницу с правильным заголовком страницы.
Название domain.com/en не содержит ни одного из слов.
Я обыскал весь проект, чтобы найти слово "ночной ястреб". Это не входит в стоимость. И у нас никогда не было никаких китайских переводов.
2 answers
Google включает в индекс нечитаемые страницы, если на них есть ссылки с других сайтов.
Это означает, что ссылка на веб-сайт, например<a href="domain.com/en">[CHINESE] - Hey nighthawk</a>, может отображаться в результатах поиска.
Некоторые предположили, что такие случаи являются временными. Они не всегда такие. Google индексирует недоступные страницы, потому что иногда важные страницы блокируются robots.txt . Мэтт Каттс объясняет:
Вы можете задаться вопросом, почему Google иногда возвращает неразборчивый URL-адрес ссылка, даже если Googlebot было запрещено сканировать этот URL-адрес с помощью robots.txt файл. Для этого есть довольно веская причина: когда я начинал работать в Google в 2000 году, несколько полезных веб-сайтов (eBay, New York Times, калифорнийское управление транспортных средств) имели robots.txt файлы, которые запрещали какую-либо загрузку страниц вообще. Теперь я спрашиваю вас, что мы должны возвращать в качестве результата поиска, когда кто-то выполняет запрос [калифорнийский dmv]? Мы выглядели бы довольно грустно, если бы не вернулись www.dmv.ca.gov в качестве первого результата. Но помните: нам не разрешалось извлекать страницы из www.dmv.ca.gov в этот момент. Решение состояло в том, чтобы показать непроверенную ссылку, когда у нас был высокий уровень уверенности в том, что это правильная ссылка.
Вы вряд ли увидите эту страницу в результатах поиска, за исключением запроса site:, который вы сделали. В противном случае кому-то пришлось бы искать [CHINESE] Hey nighthawk или какую-то его часть.
Robots.txt предотвращает то, чтобы страницы были специально неиндексируемыми
Вы правильно поняли.
Сделайте страницу доступной для обхода и неиндексируемой
Чтобы убедиться, что страница не отображается в результатах поиска Google, убедитесь, что она доступна для обхода с помощью robots.txt, и явно неиндексируемый.
Это обычная практика использования robots.txt в попытке не допустить попадания страниц в индексы поисковых систем. Однако, чтобы гарантировать, что страница не попадет проиндексированный, он должен быть доступен для обхода.
Google (и Bing) исключат страницу из индекса по указанию страницы. Это может быть HTTP-заголовок X-Robots-Tag или метатег noindex в HTML.
Но Googlebot не сможет прочитать эти инструкции, если robots.txt запрещает им читать эту страницу. Поэтому Google использует преимущество сомнения и помещает страницу в индекс (если им нравится).
Вот как Google объясняет это:
После robots.txt файл (или его отсутствие) дал разрешение на обход страницы, по умолчанию страницы обрабатываются как доступные для обхода, индексируемые, архивируемые , и их содержимое одобрено для использования во фрагментах, которые отображаются в результатах поиска, если только разрешение специально не запрещено в метатеге robots или теге X-Robots.
Неполные исправления Google
Вы можете использовать инструменты Google для веб-мастеров, чтобы временно удалить страницу из индекса Google. Но нет установленного времени на то, как долго удаление полезно для. На самом деле это не решение проблемы.
У Google также есть экспериментальная функция без индекса в robots.txt , который предназначен для того, чтобы веб-мастера могли просматривать страницы как без обхода, так и без индексации. Поскольку Google не дает никаких гарантий относительно его функциональности, используйте его на свой страх и риск.
Кроме того, имейте в виду, что другие поисковые системы не поддерживают директивы без индекса внутри robots.txt . Документация веб-мастера Bing гласит:
Чтобы удалить URL-адрес из своего собственного сайт из индекса Bing... Bingbot должен иметь доступ к URL-адресу, поэтому вы не должны блокировать повторный просмотр URL-адреса robots.txt .
Что такое robots.txt для чего же тогда?
Robots.txt предназначен в качестве решения для обеспечения того, чтобы боты поисковых систем не создавали нежелательный трафик-паук на веб-сайтах - за этот трафик может взиматься плата с веб-хостинга или (если ваш веб-сайт уязвим) могут возникнуть проблемы с производительностью или стабильностью.
Они (якобы) разделены опасения из-за нежелания, чтобы ваши страницы были доступны для поиска пользователями в Google.
О тарабарщине, связанной с вашей страницей в поисковой выдаче
Неверный контент в результатах поиска, связанный с вашей страницей, может быть получен из якорного текста страниц, связанных с вашим сайтом. Поскольку страница недоступна для просмотра , эта информация из вторых рук может быть лучшей доступной информацией Google о содержимом вашей страницы.
Казалось бы, что часть контента, получающего связанный с вашим сайтом из более темных областей Интернета. Эти места могут ссылаться на ваш сайт по ряду причин, большинство из которых связаны с попытками связать себя с вашей хорошей репутацией.