Как отрицать (не выбирать) с регулярными выражениями? в PHP или JavaScript
дополнительные сведения
я нашел в интернете следующие два способа отрицания:
?![^\w]
но мне не удается найти документацию на испанском и английском языках, которую они используют для описания работы, я считаю ее слишком продвинутой, чтобы понять значение обоих и как правильно использовать их для получения ожидаемого результата. Текущий ответ устраняет проблему, но не дает определения использование.
постановка проблемы
я хочу выбрать все те слова, которые не заключены в кавычки внутри текста. Я знаю, как сделать иначе.
пример:
Lorem ipsum "боль sit amet" , consectetur adipiscing elit, maecenas est felis "sit amet".
со следующим регулярным выражением вы можете взять слова, которые находятся в скобках:
/"([\w\s]+)"/gim
результат
[
1 => 'dolor sit amet',
2 => 'sit amet'
]
что я ищу
[
1 => 'Lorem ipsum ',
2 => ', consectetur adipiscing elit, maecenas est felis ',
3 => '.',
]
Другим примером может быть следующий список:
- Привет
- Hol@
- hol.
- hol *
- Холо
печать / выбор тех, которые не используют буквенно-цифровые символы (я знаю, как взять те, которые противоречат заданному указанию). Взять все, что не является буквенно-цифровым символом, взять все те слова, которые не имеют "l", взять все, что не начинается с буквы"z", и т. д.
функциональный пример: http://www.regextester.com/15
я ожидал бы сделать что-то вроде этого для всего, что не начинается с "а":
/!^a.*/
но, очевидно, это не работает для меня, я жду вашей обратной связи.
разъяснение
я также хотел бы понять решение, которое они поднимают, а не просто copy-paste для решения проблемы.
Примечание: регулярное выражение я цитирую здесь, чтобы получить текст я он работает на PHP и JavaScript (языки, которые я использую, чтобы решить эту проблему), я видел, что есть небольшие вариации регулярных выражений на разных языках, но между ними 2 не является чем-то существенным. Поэтому я хотел бы, чтобы предлагаемое решение работало на одном из 2.
источники поддержки
4 answers
Я добавляю этот ответ как информацию, связанную с регулярными выражениями. Это мой первый ответ на SO на испанском языке, и это не перевод, поэтому, если он неверен, я могу удалить или исправить его.
Относительно того, что вы прокомментировали в своем вопросе:
(?! ) -> conocido como Negated lookahead en inglés
[^\w] -> conocido como Character class en inglés (en este caso negada)
Это два разных понятия. С одной стороны, у вас есть то, что считается lookaround, а с другой стороны, character class. Они работают следующим образом:
Lookarounds
Все lookaround, можно понять как разные способы увидеть, предшествует ли шаблон (или нет) или сменяется другим шаблоном. Например, выражение hola(?!chau) будет делать matching слова hola до тех пор, пока слово chau ниже не существует.
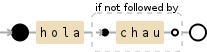
То есть:
hola, ¿qué tal? <-- OK
hola SO <-- OK
holachau <-- Falla
Ваш вопрос связан с "как отрицать", но я также хотел упомянуть, что lookarounds делятся на:
-
Lookahead (см. вперед):
-
Positive : определяется как
hola(?=chau)и будет сопоставлять слово привет только в том случае, если ниже существует чау -
(RH -) определяется как
hola(?!chau)и будет matchear слово Привет только если тогда НЕ есть чау
-
Positive : определяется как
-
Lookbehind (см. назад):
-
Positive: определяется как
(?<=chau)holaи будет сопоставлять слово Привет только если существует чау до Привет -
(RH -) определяется как
(?<!chau)holaи будет matchear слово Привет только если НЕ есть чау до Привет
-
Positive: определяется как
Важно отметить, что lookbehind не поддерживаются Javascript во всех браузерах (просмотр совместимости).
Вы можете найти больше информации о lookarounds в:
http://www.regular-expressions.info/lookaround.html
Character classes (Классы символов)
С другой стороны, существуют character class, чем в английском способ понять бы, как набор символов (или класса символов) и используется с помощью скобки [..].
То есть, если у нас есть [aeiou], он будет делать только matching с гласными без тильды.

Точно так же класс может быть отрицан, как вы упомянули, используя ^ в начале ... поэтому [^aeiou] в этом случае вы будете делать matching с символом, который не является гласным без Тильды.

Aca есть больше информации о character classes:
http://www.regular-expressions.info/charclass.html
Глаголы
Теперь, после того, как дать вам немного контекста. Если вы хотите использовать регулярные выражения, чтобы взять / сопоставить все слова, которые не заключены в кавычки, тогда PCRE (Perl-совместимые регулярные выражения, поддерживаемые PHP, R, Delphi и другими) имеет глаголы, которые очень полезны в вашем случае.
Наиболее известными являются (*SKIP) и (*FAIL), которые обычно используются вместе и обычно используются следующим образом:
".*?"(*SKIP)(*FAIL)|(\w+)
Этот тип шаблонов обычно называют техника отбросьте (discard technique), и они всегда используют одну и ту же форму шаблонов, разделеннуюOR:
patrón de descarte 1|patrón de descarte 2|patrón de descarte N|(GUARDAR ESTO)

Таким образом, приведенное выше выражение ".*?"(*SKIP)(*FAIL)|(\w+) отбрасывает все совпадения того, что было до skip и fail (".*?"), и захватывает последний шаблон (который использует круглые скобки... круглые скобки используются для захвата содержимого).
Регулярное выражение ".*?"(*SKIP)(*FAIL)|(\w+) объясняется следующим образом:
".*?" Lo uso para buscar lo que SI quiero descartar, y para indicarle
al engine que descarte agrego (*SKIP)(*FAIL)
|(\w+) o (si el patrón no se descarta) busco las palabras y las capturo
Таким образом, в приведенной выше ссылке, когда примените это выражение к тексту:
Lorem ipsum" боль sit amet", consectetur adipiscing elit, maecenas est felis"sit amet".
Захватывается следующее содержимое:
MATCH 1
1. [0-5] `Lorem`
MATCH 2
1. [6-11] `ipsum`
MATCH 3
1. [30-41] `consectetur`
MATCH 4
1. [42-52] `adipiscing`
MATCH 5
1. [53-57] `elit`
MATCH 6
1. [59-67] `maecenas`
MATCH 7
1. [68-71] `est`
MATCH 8
1. [72-77] `felis`
Вывод, регулярные выражения, на мой взгляд, впечатляют, но только если они знают, как использовать. В моем личном случае я не могу жить без них, но, как и все... чтобы забить гвоздь, нужен молоток, а не отвертка. В случае регулярных выражений они отлично подходят для pattern matching, но если вам нужна логика, то это определенно не правильный инструмент.
Лучше всего в этих случаях идти по легкому пути(Regexp-это ад). Так что, если у вас уже есть, как найти то, что вы не хотите найти с
/"([\w\s]+)"/gim
Тогда проще всего использовать preg_split чтобы очистить все, что соответствует этому выражению
preg_split("/\"([\w\s]+)\"/", $input_line);
Запуск этого в строке, которую вы имеете в качестве примера, вернет вам три блока, которые являются блоками, которые не содержатся в кавычках
[
1 => 'Lorem ipsum ',
2 => ', consectetur adipiscing elit, maecenas est felis ',
3 => '.',
]
Если вы хотите получить то, что будет удалено, вы делаете сначала preg_match() и тогда вы можете сделать нормальное разделение строки, используя explode без необходимости preg_split.
Вы, конечно, можете использовать preg_split но это будут ненужные циклы обработки.
Для другого случая немного проще
Все, что имеет не буквенно-цифровые символы
Привет
Hol@
хол.
hol *
Холо
Печать / выбор тех, которые не используются буквенно-цифровые символы
Просто используйте диапазон отрицается как это выражение, которое отмечает все не буквенно-цифровые символы
[^a-zA-z0-9]+
Уже с этим выражением вы можете получить входы, которые делают mathc, используя preg_grep
preg_grep("/[^a-zA-z0-9]+/", explode("\n", $input_lines));
Output
array(3
1 => Hol@
2 => hol.
3 => hol*
)
Все, что не начинается с
- рис
- поцелуй
- академия
- фото
- игра
- искусство
С этим выражением: ^[^a]+
preg_grep("/^[^a]+/", explode("\n", $input_lines));
Output
array(3
1 => beso
3 => foto
4 => juego
)
Если вы используете следующее регулярное выражение:
"([\w ]*)"
Или, точнее, что-то похожее на следующий код:
<?php
$str = "Lorem ipsum \"dolor sit amet\", consectetur adipiscing elit, maecenas est felis \"sit amet\".";
$array = preg_split("/\"([\\w ]*)\"/", $str, -1,
PREG_SPLIT_NO_EMPTY | PREG_SPLIT_DELIM_CAPTURE);
print_r($array);
?>
Вы получаете следующий вывод:
Array
(
[0] => Lorem ipsum
[1] => dolor sit amet
[2] => , consectetur adipiscing elit, maecenas est felis
[3] => sit amet
[4] => .
)
вид демо онлайн.
Если вы посмотрите в документации по функции preg_split, вы обнаружите, что флаг PREG_SPLIT_NO_EMPTY удаляет пустые строки из вывода, а флаг PREG_SPLIT_DELIM_CAPTURE возвращает часть регулярного выражения в скобках в результате.
Примечание: ответ Федерико Пьяцца отличный, прочитайте это в первую очередь.
- Я хочу дополнить его тем, как это будет сделано в JavaScript. Федерико говорит о технике отбрасывания, но представляет ее контрольными глаголами, которые уникальны для PCRE (они не в JavaScript).
Метод отбрасывания (также называемый" лучший трюк Regex " RexEgg)
- Работает на JavaScript.
Это очень просто, состоит из
/lo que no quieras|(esto sí)/
Вот и все!
Этот "трюк" основан на том, что он эффективно будет соответствовать тому, что вы не хотите, чтобы соответствовать, но вот трюк: он не будет пойман! Это тонкое различие-это то, что позволит нам узнать, совпало ли оно с нашим исключением или совпало с тем, что мы хотели соответствовать.
Круглые скобки в (esto sí) создают группу, и, как и любая группа, когда они соответствуют тексту, они захватывают его ... это это означает, что они получают отдельно в результате RegExp.exec() или из String.matchAll(). Таким образом, это просто вопрос проверки того, было ли что-то поймано в группе 1 или нет.
Возьмем пример вопроса: выберите весь текст, за исключением частей в кавычках.
/".*?"|([^"]+)/g
Код:
const regex = /".*?"|([^"]+)/g,
texto = 'Lorem ipsum "dolor sit amet", consectetur adipiscing elit, maecenas est felis "sit amet".';
let resultado =
[ ...texto.matchAll(regex) ] //obtenemos todas las coincidencias
.filter(match => match[1] !== undefined) //excepto si no capturaron en grupo 1
.map(match => match[0]); //nos quedamos con la coincidencia
console.log(resultado);