Список функций Big-O для PHP
После использования PHP в течение некоторого времени я заметил, что не все функции PHP встроены так быстро, как ожидалось. Рассмотрим ниже две возможные реализации функции, которая определяет, является ли число простым, используя кэшированный массив простых чисел.
//very slow for large $prime_array
$prime_array = array( 2, 3, 5, 7, 11, 13, .... 104729, ... );
$result_array = array();
foreach( $prime_array => $number ) {
$result_array[$number] = in_array( $number, $large_prime_array );
}
//speed is much less dependent on size of $prime_array, and runs much faster.
$prime_array => array( 2 => NULL, 3 => NULL, 5 => NULL, 7 => NULL,
11 => NULL, 13 => NULL, .... 104729 => NULL, ... );
foreach( $prime_array => $number ) {
$result_array[$number] = array_key_exists( $number, $large_prime_array );
}
Это связано с тем, что in_array реализован с линейным поиском O(n), который будет линейно замедляться по мере роста $prime_array. Где функция array_key_exists реализована с помощью хэш-поиска O(1), который не замедлится, если хэш-таблица не станет чрезвычайно заполненный (в этом случае это только O(n)).
До сих пор мне приходилось открывать большие буквы методом проб и ошибок, а иногда просматривая исходный код . Теперь перейдем к вопросу...
Был ли список теоретических (или практических) больших O раз для всех* встроенных функций PHP?
*или, по крайней мере, интересные из них
Например, очень трудно предсказать, какое большое число функций перечислено, потому что возможная реализация зависит от неизвестные основные структуры данных PHP: array_merge, array_merge_recursive, array_reverse, array_intersect, array_combine, str_replace (с входными данными массива) и т. Д.
4 answers
Поскольку не похоже, что кто-то делал это раньше, я подумал, что было бы неплохо иметь это где-нибудь для справки. Я пошел, хотя и либо через бенчмарк, либо через просмотр кода, чтобы охарактеризовать функции array_*. Я попытался поместить более интересную букву "О" ближе к вершине. Этот список неполон.
Примечание: Все Большие O, где вычисляется при условии, что поиск хэша равен O(1), хотя на самом деле это O(n). Коэффициент n настолько мал, что затраты оперативной памяти на хранение большого достаточное количество массивов повредит вам, прежде чем характеристики lookup Big-O начнут действовать. Например, разница между вызовом array_key_exists при N=1 и N=1 000 000 составляет ~50% увеличения времени.
Интересные Моменты:
-
isset/array_key_existsнамного быстрее, чемin_arrayиarray_search -
+(объединение) немного быстрее, чемarray_merge(и выглядит приятнее). Но это работает по-другому, так что имейте это в виду. -
shuffleнаходится на том же уровне Big-O, что иarray_rand -
array_pop/array_pushбыстрее, чемarray_shift/array_unshiftиз-за штрафа за повторную индексацию
Поисковые запросы:
array_key_exists O(n), но очень близко к O(1) - это связано с линейным опросом при столкновениях, но поскольку вероятность столкновений очень мала, коэффициент также очень мал. Я нахожу, что вы относитесь к хэш-поискам как к O(1), чтобы дать более реалистичный большой O. Например, разница между N=1000 и N=100000 составляет всего около 50% замедления.
isset( $array[$index] ) O(n) но действительно близко к O(1) - он использует тот же поиск, что и array_key_exists. Поскольку это языковая конструкция, она будет кэшировать поиск, если ключ жестко закодирован, что приведет к ускорению в случаях, когда один и тот же ключ используется повторно.
in_array O(n) - это потому, что он выполняет линейный поиск по массиву, пока не найдет значение.
array_search O(n) - он использует ту же основную функцию, что и in_array, но возвращает значение.
Функции очереди:
array_push O(∑ var_i, для всех i)
array_pop O(1)
array_shift O(n) - он должен переиндексировать все ключи
array_unshift O(n + ∑ var_i, для всех i) - он должен переиндексировать все ключи
Пересечение массивов, Объединение, Вычитание:
array_intersect_key если пересечение 100% делает O(Max(param_i_size)*∑param_i_count, для всех i), если пересечение 0% пересекает O(∑param_i_size, для всех i)
array_intersect если пересечение 100% делает O(n^2*∑param_i_count, для всех i), если пересечение 0% пересекается O(n^2)
array_intersect_assoc если пересечение 100% делает O(Max(param_i_size)*∑param_i_count, для всех i), если пересечение 0% пересекает O(∑param_i_size, для всех i)
array_diff O(π парам_и_размер, для всех i) - Это произведение всех парам_размеров
array_diff_key O(∑ param_i_size, для i !=1) - это потому, что нам не нужно перебирать первый массив.
array_merge O( ∑ array_i, i !=1) - не нужно перебирать первый массив
+ ( объединение) O(n), где n - размер 2-го массива (т.е. array_first + array_second) - меньше накладных расходов, чем array_merge, так как ему не нужно перенумеровывать
array_replace O( ∑ массив_i, для всех i)
Случайный:
shuffle O(n)
array_rand O(n) - Требуется линейный опрос.
Очевидный Большой-О:
array_fill O(n)
array_fill_keys O(n)
range O(n)
array_splice O(смещение + длина)
array_slice O(смещение + длина) или O(n), если длина = НОЛЬ
array_keys O(n)
array_values O(n)
array_reverse O(n)
array_pad O(размер подложки)
array_flip O(n)
array_sum O(n)
array_product O(n)
array_reduce O(n)
array_filter O(n)
array_map O(n)
array_chunk O(n)
array_combine O(n)
Я хотел бы поблагодарить Eureqa за то, что он упростил поиск большого числа функций. Это удивительная бесплатная программа, которая может найти наиболее подходящую функция для произвольных данных.
ИЗМЕНИТЬ:
Для тех, кто сомневается, что поиск в массиве PHP O(N), я написал тест, чтобы проверить это (они по-прежнему эффективны O(1) для наиболее реалистичных значений).
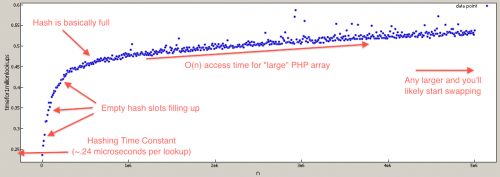
$tests = 1000000;
$max = 5000001;
for( $i = 1; $i <= $max; $i += 10000 ) {
//create lookup array
$array = array_fill( 0, $i, NULL );
//build test indexes
$test_indexes = array();
for( $j = 0; $j < $tests; $j++ ) {
$test_indexes[] = rand( 0, $i-1 );
}
//benchmark array lookups
$start = microtime( TRUE );
foreach( $test_indexes as $test_index ) {
$value = $array[ $test_index ];
unset( $value );
}
$stop = microtime( TRUE );
unset( $array, $test_indexes, $test_index );
printf( "%d,%1.15f\n", $i, $stop - $start ); //time per 1mil lookups
unset( $stop, $start );
}
Вы почти всегда хотите использовать isset вместо array_key_exists. Я не смотрю на внутренние компоненты, но я почти уверен, что array_key_exists - это O(N), потому что он перебирает каждый ключ массива, в то время как isset пытается получить доступ к элементу, используя тот же алгоритм хэширования, который используется при доступе к индексу массива. Это должно быть O(1).
Один "попался", на который стоит обратить внимание, это:
$search_array = array('first' => null, 'second' => 4);
// returns false
isset($search_array['first']);
// returns true
array_key_exists('first', $search_array);
Мне было любопытно, поэтому я сравнил разницу:
<?php
$bigArray = range(1,100000);
$iterations = 1000000;
$start = microtime(true);
while ($iterations--)
{
isset($bigArray[50000]);
}
echo 'is_set:', microtime(true) - $start, ' seconds', '<br>';
$iterations = 1000000;
$start = microtime(true);
while ($iterations--)
{
array_key_exists(50000, $bigArray);
}
echo 'array_key_exists:', microtime(true) - $start, ' seconds';
?>
is_set: 0,132308959961 секундыarray_key_exists: 2.33202195168 секунды
Конечно, это не показывает временной сложности, но показывает, как эти 2 функции сравниваются друг с другом.
Чтобы проверить сложность по времени, сравните время, необходимое для запуска одной из этих функций на первом ключе и последнем ключе.
Объяснение случая, который вы конкретно описываете, заключается в том, что ассоциативные массивы реализованы в виде хэш-таблиц, поэтому поиск по ключу (и, соответственно, array_key_exists) равен O(1). Однако массивы не индексируются по значению, поэтому в общем случае единственным способом определить, существует ли значение в массиве, является линейный поиск. В этом нет ничего удивительного.
Я не думаю, что существует конкретная всеобъемлющая документация по алгоритмической сложности методов PHP. Однако, если это большой достаточно беспокойства, чтобы оправдать усилия, вы всегда можете просмотреть исходный код.
Если бы у людей на практике возникали проблемы с конфликтами ключей, они бы реализовали контейнеры со вторичным поиском хэша или сбалансированным деревом. Сбалансированное дерево дало бы O(log n) наихудшее поведение и O(1) среднее значение (сам хэш). Накладные расходы не стоят того в большинстве практических приложений с памятью, но, возможно, существуют базы данных, которые реализуют эту форму смешанной стратегии в качестве варианта по умолчанию.