Как Разработать Схему Базы Данных Для Древовидной Структуры (Ориентированный ациклический Граф)
Я использую нижеприведенную древовидную структуру и планирую разработать схему бд для приведенного ниже.
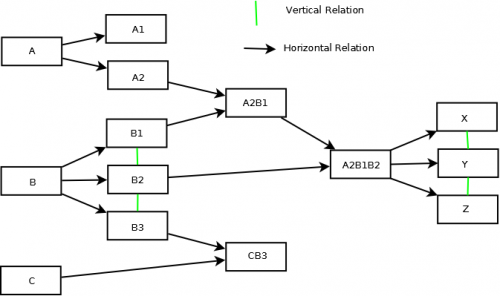
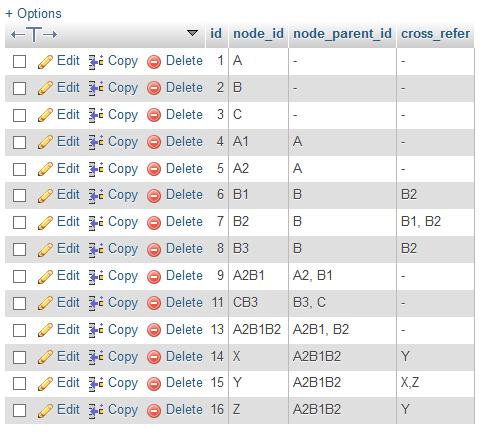
То, что у меня есть до сих пор, описано ниже,
Проблема, с которой я сталкиваюсь, заключается в том, что если я ищу Y, должно быть сгенерировано дерево ниже.
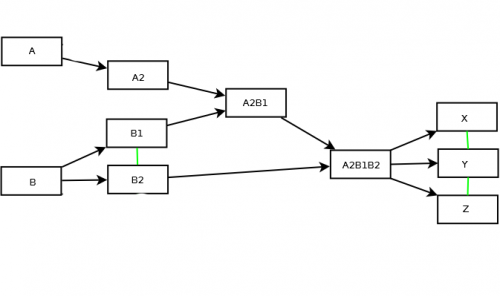
Логика, которую я использую, заключается в том, что Y имеет две перекрестные ссылки X, Z, эти два узла должны быть на диаграмме и родительские узлы вплоть до начального родительского узла.
Учитывая, что я использую PHP для создайте это дерево, используя таблицу базы данных mysql, как показано выше. Структура БД может быть изменена. Я искал в Google похожую древовидную структуру, но не смог найти никакой помощи.
Примечание
Я не прошу вас написать код для меня. Все, о чем я прошу, - это несколько рекомендаций, как это должно быть сделано.
Я нашел ниже полезное, но все же отличное от моего сценария
Каков наиболее эффективный/элегантный способ разбора плоской таблицы на дерево?
Как представить древовидную структуру в бд
Если кто-нибудь может, пожалуйста, скажите мне, какие библиотеки php следует использовать для создания дерева и какую подходящую структуру бд следует использовать?
7 answers
Структура вашей базы данных не нормализована, потому что у вас есть несколько идентификаторов как в node_parent_id, так и в cross_refer. Вы должны разделить эту информацию на отдельные таблицы.
Итак, у вас будет ваша таблица nodes, а также вторая таблица для описания отношений "родитель- потомок"; в этой таблице будет идентификатор дочернего узла и идентификатор родительского узла.
Перекрестные ссылки должны быть в третьей таблице, в которой снова есть два столбца идентификаторов узлов, но вы можете сделать это двумя способами, потому что перекрестные ссылки являются двунаправленными. Один из способов - хранить каждую перекрестную ссылку только один раз, что означает, что при запросе таблицы вам нужно проверить обе возможности (перекрестная ссылка между X и Y может храниться с X в первом столбце и Y во втором столбце или наоборот, поэтому, чтобы найти X, вам придется проверить оба столбца). Другой способ - хранить каждую перекрестную ссылку дважды, по одному разу для каждого направления. Это упрощает запрос, но сохраняет избыточные данные и может привести к несоответствиям, например, если по какой-либо причине одна ссылка удалена, а другая нет.
Поиск путей с такой структурой становится намного проще, потому что вам не нужно дополнительно анализировать строки, разделенные запятыми, что одновременно сложнее и менее эффективно.
Вы также можете использовать это для обеспечения ссылочной целостности, чтобы, например, у узла не было родительского идентификатора, которого на самом деле не существует в базе данных.
Для получения дополнительной информации, исследования "нормализация базы данных". (Или вы можете написать это с буквой "z", если вы так склонны;-P)
Ваша структура бд не похожа на дерево, это просто график.
Я предлагаю вам отказаться от реляционной базы данных для этой структуры и взглянуть на некоторые графические базы данных, такие как Neo4j , OrientDB и Бесконечный граф.
Но если вы вынуждены использовать MySQL, вы можете использовать FlockDB, который можно использовать для обхода узла MySQL (см. Строку как узел), но с некоторыми ограничениями. или вы можете протестировать другой движок MySQL, такой как OQGRAPH, который обеспечивает графический движок для MySQL и MariaDB.
Позвольте мне переформулировать вопрос, просто чтобы убедиться, что я правильно его понимаю. У вас есть узлы и два вида отношений - стрелки и вертикальные линии. Затем, учитывая узел N, вы хотите сгенерировать подмножество S(N) узлов со следующими рекурсивными правилами:
- Правило 0: N находится в S(N).
- Правило 1: Если узел M связан с N через вертикальное отношение, он также находится в S(N).
- Правило 2: Если узел M находится в S(N), то любой узел со стрелкой, указывающей на M, также находится в S(N).
Множество S(N) - это минимальный набор узлов, удовлетворяющих этим правилам.
Пример, который вы приводите с N, равным Y, похоже, подтверждает эти правила.
Однако существует другой, но (по крайней мере для меня) более естественный набор правил, где правило 1 выше заменено на
- Правило 1': Если Узел M находится в S(N), то любой Узел, связанный с M через вертикальное отношение, также находится в S(N).
В дальнейшем я буду исходить из Правил 0,1,2, подтвержденных вашим примером, но аналогичный подход может быть использован для правил 0,1', 2 или любой модификации.
Также я понимаю, что в вашей таблице в строке 7 есть ошибка, она должна быть:
7 B2 B B1,B3 (not B2,B3)
Теперь перейдем к предлагаемому решению.
Сначала я бы немного изменил структуру вашей таблицы: Поскольку "идентификатор" является вашим первичным ключом, правило для внешнего ключа состоит в том, чтобы указывать на первичный ключ соответствующей записи. То есть в вашем случае я бы заменил "node_id" на "node_name" или что-то в этом роде, просто чтобы не перепутайте с "id" и замените записи "node_parent_id" и "cross_ref" их "идентификаторами". Например, строка номер 15 будет выглядеть так:
15 'Y' [13] [14,16]
В качестве альтернативы, если вы предпочитаете по соображениям удобочитаемости, вы можете использовать A, B, X, Y и т.д. в качестве первичных ключей, конечно, при условии, что они уникальны, тогда ваша таблица останется прежней, за исключением поля "идентификатор", которое не требуется. Я возьму на себя первый случай, но вы можете адаптировать его ко второму с помощью простого замена.
Это все, что вам нужно, насколько можно судить по таблице.
Теперь вам нужна рекурсивная функция для генерации подграфа S(N) для каждого заданного узла N.
Я буду реализовывать набор S как массив $набор всех идентификаторов его узлов. Затем я определю две функции - одну для расширения набора изначально на основе правил 1,2 , а другую для последующего расширения набора только на основе правила 2.
Для простоты я предположу, что ваша таблица импортирована в память как ассоциативный массив $строк строк, такой, что $rows[$id] представляет строку с "идентификатором", равным $id, как, опять же, ассоциативный массив. Итак
$rows[15] = array('id'=>15,
'node_name'=>'Y',
'node_parent_id'=>array(13),
'cross_ref'=>array(14,16)
);
Вот код для функций:
function initial_expand_set ($node_id) {
global($rows); // to access the array from outside
$set = array($node_id); // Rule 0
$row = $rows[$node_id]; // Get current Node
$parents = $row['node_parent_id']; // Get parents of the Node
$set = $parents ? array_merge ($set, $parents) : $set; // Join parents to the set
$vert_brothers = $row['cross_ref']; // Get vertical relations
$set = $vert_brothers ? array_merge ($set, $vert_brothers) : $set;
$set = expand_set($set); // Recursive function defined below
return $set;
}
И рекурсивная функция:
// iterate over nodes inside the set, expand each node, and merge all together
function expand_set (array $set) {
global($rows);
$expansion = $set; // Initially $expansion is the same as $set
foreach ($set as $node_id) {
$row = $rows[$node_id]; // Get Node
// Get the set of parents of the Node - this is our new set
$parents = $row['node_parent_id']; // Get parents of the Node
// apply the recursion
$parents_expanded = expand_set($parents);
// merge with previous expansion
$expansion = array_merge($expansion, $parents_expanded);
}
// after the loop is finished getting rid of redundant entries
// array_unique generates associative array, for which I only collect values
$expansion = array_values( array_unique($expansion) );
return $expansion;
}
Надеюсь, это сработает для вас. :)
Если потребуются какие-либо дополнительные подробности или объяснения, я буду рад помочь.
ПС. Для педантов среди читателей обратите внимание, что я использую пробел перед "(" для определения функции и нет места для вызовов функций, как рекомендовано Дугласом Крокфордом.
Единственная библиотека PHP, которую я нашел для работы с графиками, - это пакет PEAR "structure_graph" (http://pear.php.net/manual/en/package.structures.structures-graph.php ). В настоящее время он не поддерживается, важные функции (например, удаление узла) не реализованы, и открыты серьезные ошибки (например, невозможность установки под Windows 7). Не похоже, что этот пакет в его нынешнем виде был бы полезен.
Основные операции, необходимые для управления вашим график можно разделить на те, которые изменяют график (мутируют), и те, которые запрашивают его (не мутируют).
Операции мутации
- createNode($nodeName), возвращает $NodeID – Обратите внимание, что при создании узлов у них нет ребер, соединяющих их с другими узлами в графике.
- deleteNode($NodeID) – Для обеспечения ссылочной целостности это должно быть разрешено только в том случае, если все ребра, соединяющиеся с узлом, ранее были удалены, и возникло исключение в противном случае.
- Имя обновления ($NodeID, $newnodename) – Если разрешено изменять имя существующего узла.
- createhorizontaledge($soucenodeid, $destinationnodeid) – это направленное ребро. Создает исключения, если ребро уже существует, или если добавление ребра создает цикл.
- Удалить горизонталь ($sourcenodeid, $destinationnodeid)
- Createverticaledge($FIRSTNODEID, $secondnodeid) – Это двунаправленное ребро, идентификаторы первого и второго узлов могут быть переключается, и эффект на графике будет таким же. Создает исключение, если ребро уже существует или если два узла не имеют одного и того же горизонтального родителя.
- deleteverticaledge($firstnodeid, $secondnodeid) – Поскольку ребро не направлено, оно удалит ребро, даже если аргументы были в обратном порядке для создания.
Примеры: Чтобы вручную построить раздел вашего графика с именами узлов, начинающимися с "B", код будет следующим:
$nodeID_B = CreateNode(“B”);
$nodeID_B1 = CreateNode(“B1”);
$nodeID_B2 = CreateNode(“B2”);
$nodeID_B3 = CreateNode(“B3”);
CreateHorizontalEdge($nodeID_B, $nodeID_B1);
CreateHorizontalEdge($nodeID_B, $nodeID_B2);
CreateHorizontalEdge($nodeID_B, $nodeID_B3);
CreateVerticalEdge($nodeID_B1, $nodeID_B2);
CreateVerticalEdge($nodeID_B2, $nodeID_B3);
Код для ручного удалите узел с именем "B3":
// Must remove all edges that connect to node first
DeleteVerticalEdge($nodeID_B2, $nodeID_B3);
DeleteHorizontalEdge($nodeID_B, $nodeID_B3);
// Now no edges connect to the node, so it can be safely deleted
DeleteNode($nodeID_B3);
Операции без изменений
- nodeexists($NodeID) – Возвращает значение true/false
- getnodeidbyname($имя_узла) – Возвращает $NodeID
- Получить имя ($NodeID)
- horizontaledgeexists($sourcenodeid, $destinationnodeid) – Возвращает значение true/false
- verticaledgeexists($firstnodeid, $secondnodeid) – Возвращает значение true/false, одинаковый результат независимо от порядка аргументов.
- Горизонтальное соединение существует($startnodeid, $endnodeid) – Возвращает true/false – Следуя горизонтальным стрелкам, есть ли путь от начального узла до конечного узла? Чтобы проверить, приведет ли создание нового горизонтального ребра от $nodeid1 до $nodeid2 к созданию цикла, вызовите HorizontalConnectionExists ($nodeid2, $nodeid1).
- gethorizontalancestornodes($NodeID) – Возвращает массив всех узлов, от которых к узлу аргумента ведут горизонтальные пути.
- gethorizontaldescendentnodes($NodeID) – Возвращает массив всех узлов, которые имейте горизонтальные пути, ведущие от узла аргумента к узлу аргумента.
- getverticalsiblingnodes($NodeID) – Возвращает массив всех узлов, которые имеют вертикальные соединения с узлом аргумента. Поскольку (согласно вашему ответу на мой уточняющий вопрос) вертикальные отношения не являются транзитивными, функция VerticalEdgeExists (выше) является единственной, необходимой для запроса вертикальных отношений.
Пример: Чтобы получить список узлов, которые будут включены в поддерево, которое вы описываете в ваш вопрос, объедините результаты GetHorizontalAncestorNodes($NodeID) и getverticalsiblingnodes($NodeID).
Структуры данных
Вам всегда понадобится таблица "Узлы" для хранения идентификатора узла и имени узла. Эта таблица может быть расширена для хранения другой информации, связанной с узлами.
Поскольку вертикальные ребра не являются транзитивными, информацию о них можно просто поместить в таблицу "Вертикальные ребра" со столбцами vedgeid, firstNodeID, secondNodeID.
Существуют несколько вариантов хранения информации о горизонтальном крае. С одной стороны, структуры данных и операции изменения могут быть простыми, но за счет замедления и усложнения некоторых операций запроса. С другой стороны, структуры данных могут быть немного сложнее, но, возможно, намного больше (в худшем случае экспоненциально увеличиваться с увеличением числа узлов), с более сложными операциями изменения, но более простыми и быстрыми запросами. Решение о том, какая реализация лучше всего подходит для вас, будет зависит от размера ваших графиков и от того, как часто они меняются по сравнению с количеством запросов к ним.
Я опишу три возможные структуры данных для представления графика, переходя от простого к сложному. Я подробно остановлюсь на алгоритмах перечисленных выше операций только для последнего набора структур данных. Я думаю, что этот набор структур лучше всего подходит для небольших графиков с высоким соотношением запросов к изменениям.
Обратите внимание, что все структуры данных имеют Таблицы "Узлы" и "Вертикальные ребра", которые я обсуждал выше.
Минимальная структура данных
Первая структура данных содержит таблицу "Горизонтальные границы" со столбцами hedgeid, sourcenodeid и destinationNodeID. Функции изменения просты, и большая часть кода будет кодом проверки ошибок, который создает исключения. Не изменяющие функции horizontalconnectionсуществуют, Gethorizontalancestornodes и GetHorizontalDescendentNodes будут сложными и потенциально медленными. Каждый раз, когда они вызванные, они будут рекурсивно пересекать таблицу HorizontalEdges и собирать идентификаторы узлов. Эти коллекции возвращаются непосредственно для двух последующих функций, в то время как HorizontalConnectionExists может завершать и возвращать значение true, если он находит конечный узел при поиске потомков начального узла. Он вернет значение false, если поиск завершится без поиска конечного узла.
Таблица переходных замыканий
Вторая структура данных также имеет таблицу HorizontalEdges, идентичную таблице описано выше, но также имеет вторую таблицу "Horizontaltransitiveclosures" со столбцами HTCID, startnodeid и endnodeid. В этой таблице есть строка для каждой пары начального узла и конечного узла, так что путь с использованием горизонтальных ребер можно проследить от начального узла до конечного узла.
Пример: Для графика в вопросе строки в этой таблице, включающие узел A (для упрощения обозначения я буду использовать имена, а не целочисленные идентификаторы узлов для идентификации узлов, и опущу hTCID столбец) являются:
A, A2
A, A2B1
A, A2B1B2
A, X
A, Y
A, Z
Строки, включающие узел A2B1 (первый также находится в наборе выше), следующие:
A, A2B1
A2, A2B1
B, A2B1
B1, A2B1
A2B1, A2B1B2
A2B1, X
A2B1, Y
A2B1, Z
В худшем случае эта таблица масштабируется как квадрат числа узлов.
С этой структурой данных существует горизонтальное соединение, Gethorizontalancestornodes и GetHorizontalDescendentNodes могут быть реализованы в виде простых поисков в таблице HorIzontaltraNsitivecloSures. Сложность перемещается в раздел CreateHorizontalEdge и удаляет раздел Horizontaledge функции. DeleteHorizontalEdge особенно сложен и требует довольно подробного объяснения того, почему алгоритм работает.
Транзитивное замыкание с путями
Окончательная структура данных, которую я буду обсуждать, хранит информацию о горизонтальных краях в двух таблицах. Первый, "Horizontaltransitiveclosurepaths", содержит столбцы HTCPATHID, startnodeid, endnodeid, длина пути. Вторая таблица "Ссылки на пути" содержит столбцы pathlinkid, htcpathid, sourcenodeid, destinationNodeID.
В Таблица HorizontalTransitiveClosurePaths аналогична таблице horizontaltransitiveclosures в структуре данных, описанной выше, но в ней есть по одной строке для каждого возможного пути, который может выполнить транзитивное замыкание, а не по одной строке на транзитивное замыкание. Например, на графике, показанном в вопросе, в таблице HorizontalTransitiveClosures будет одна строка (B, A2B1B2) (сокращенная запись, как указано выше) для закрытия, которое начиналось в B и заканчивалось A2B1B2. То Таблица HorizontalTransitiveClosurePaths будет содержать две строки: (10, B, A2B1B2, 3) и (11, B, A2B1B2, 2), поскольку существует два способа перехода от B к A2B1B2. Таблица ссылок на пути описывает каждый из этих путей с одной строкой на ребро, образующее путь. Для двух путей от B до A2B1B2 строки следующие:
101, 10, B, B1
102, 10, B1, A2B1
103, 10, A2B1, A2B1B2
104, 11, B, B2
105, 11, B2, A2B1B2
Нет необходимости в таблице Horizonaledges, так как края можно найти, выбрав строки в таблице HorizontalTransitiveClosurePaths длиной 1.
В функции запроса реализованы так же, как и в структуре данных с транзитивным замыканием, описанной выше. Поскольку для замыкания может существовать несколько путей, необходимо будет использовать оператор GROUP BY. Например, запрос SQL, который возвращает все узлы, являющиеся предками узла с идентификатором:nodeid, является: ВЫБЕРИТЕ startnodeid из HorizontalTransitiveClosurePaths, ГДЕ endnodeid= : группа nodeid ПО startnodeid
Чтобы реализовать DeleteHorizontalEdge, выполните поиск по ссылкам пути для HTCPATHID всех пути, содержащие ребро. Затем удалите эти пути из таблицы HorizontalTransitiveClosurePaths и все ребра, связанные с путями из таблицы Pathlinks.
Для реализации createhorizontaledge ($soucenodeid, $destinationnodeid) сначала выполните поиск в таблице HorizontalTransitiveClosurePaths путей, которые заканчиваются на $soucenodeid – это "набор путей предка". Найдите в HorizontalTransitiveClosurePaths пути, которые начинаются с destinationnodeid – это "набор путей потомков". Теперь вставьте новые пути из следующих 4 групп (некоторые из которых могут быть пустыми) в таблицу HorizontalTransitiveClosurePaths и вставьте ссылки для этих путей в таблицу Pathlinks.
- Путь длиной 1 от $soucenodeid до $destinationnodeid Длина пути от $soucenodeid до $destinationnodeid
- Для каждого пути в наборе путей-предков новый путь, который расширяет конец пути на одну дополнительную ссылку от $soucenodeid до $destinationnodeid
- Для каждого пути в наборе путей-потомков новый путь, который расширяет начало пути одной дополнительной ссылкой с $soucenodeid до $destinationnodeid
- Для каждой комбинации одного пути из набора путей предка и одного пути из набора путей потомка, путь, созданный путем среза пути предка, к ссылке из $soucenodeid в $destinationnodeid, к пути потомка.
Пример: График состоит из 6 узлов: A1, A2, B, C, D1 и D2. Он имеет 4 ребра, (A1, B), (A2, B), (C, D1), (C, D2). То Таблица HorizontalTransitiveClosurePaths (с использованием имени узла, а не номера) выглядит следующим образом:
1, A1, B, 1
2, A2, B, 1
3, C, D1, 1
4, C, D2, 1
Таблица ссылок на пути:
1, 1, A1, B
2, 2, A2, B
3, 3, C, D1
4, 4, C, D2
Теперь мы добавим ребро от B до C. Набор путей предка равен (1, 2), а набор путей потомка равен (3, 4) Пути, добавленные в каждую из 4 групп, следующие:
- Само новое ребро: Горизонтальные транзитивные пути: (5, B, C, 1); Ссылки на пути (5, 5, B, C)
- Расширьте каждый путь предка на одну ссылку в конце:
HorizontalTransitiveClosurePaths: 6, A1, C, 2 7, A2, C, 2 PathLinks: 6, 6, A1, B 7, 6, B, C 8, 7, A2, B 9, 7, B, C - Расширить каждый нисходящий путь по одной ссылке в начале:
HorizontalTransitiveClosurePaths: 8, B, D1, 2 9, B, D2, 2 PathLinks: 10, 8, B, C 11, 8, C, D1 12, 9, B, C 13, 9, C, D2 - Объединить все комбинации, содержащие один путь предка и один путь потомка:
HorizontalTransitiveClosurePaths: 10, A1, D1, 3 11, A1, D2, 3 12, A2, D1, 3 13, A2, D2, 3 PathLinks: 14, 10, A1, B 15, 10, B, C 16, 10, C, D1 17, 11, A1, B 18, 11, B, C 19, 11, C, D2 20, 12, A2, B 21, 12, B, C 22, 12, C, D1 23, 13, A2, B 24, 13, B, C 25, 13, C, D2
Дайте мне знать, если какая-либо часть ответа нуждается в дополнительном разъяснении.
Это может помочь вам
Иерархические структуры являются обычным явлением для веб-сайтов и реляционных баз данных, популярным примером может быть классический "веб-каталог", где элементы хранятся в дереве каталогов, и пользователи щелкают по структуре категорий, чтобы найти интересующие их элементы.
Классическая проблема проектирования каталогов заключается в том, как хранить отношения между категориями. Наличие пар id/parentid в таблице является простым решением и достаточно эффективным для каталогов с небольшой глубиной, но как насчет более крупных структур, таких как дамп каталога DMOZ?
Некоторые материалы для чтения по деревьям SQL могут представлять для вас интерес, если вы планируете построить большую иерархию.
С точки зрения PHP, Кевин ван Зонневельд создал небольшую приятную функцию Explodetree для представления данных в многомерном массиве.
Чтобы этот учебник не стал огромным, я бы рекомендовал прочитать первую ссылку, в частности, на разберитесь с причинами и недостатками использования древовидных структур в SQL. Еще немного чтения перед сном о вложенных наборах и иерархии данных можно найти в проекте кода. Пример древовидных структур в действии
Следующий скрипт создаст древовидную структуру и сохранит ее в MySQL. Он довольно длинный, но он должен дать вам хорошее представление о том, как использовать преимущества древовидных структур, и его достаточно легко адаптировать для ваших собственных нужд.
Это первая часть 2-й части post предоставляет вам скрипт, позволяющий создавать и хранить структуры каталогов. Примечания в нижней части страницы должны помочь вам ознакомиться со сценарием на случай, если у вас возникнут проблемы или вам будет интересно поработать с ним в соответствии с вашими собственными требованиями. 2-й пост содержит базовый графический интерфейс и функции администратора для просмотра и изменения древовидной структуры.
Если я правильно понимаю жаргон (он может быть немного тяжелым), этот скрипт представляет собой "обход дерева предварительного заказа", который может привести к новому способу анализа и экстраполяции ваших данных.
This method avoids recursion, you can fetch breadcrumbs for a category thats 14 levels, 20 levels or even 50 levels deep using one query. In this particular script both the parent and child categories are fetched in one query.
All subcategories are methodically encapsulated within their parent nodes, and each node can give you a calculation of how many subcategories there are without any further querying
Generally, for static and/or large tree structures, this structuring of your categories is advantageous for speed and ease of querying.
The cost is that updates to the tree structure can be expensive, i.e. removing or adding (and sometimes editing) a node in the middle of the tree, which requires altering all records to the 'right side' of the tree to avoid having gaps or collisions in the tree structure. In general, you want to avoid having to update a large tree often, or save the updates for one particular moment where the whole tree can be rebuilt with its updates.
Сохраните и запустите следующий сценарий для создания некоторых примеров данных. Предполагается, что у вас установлен MySQL и уже создана база данных под названием "тест". Загрузите этот 300-тысячный список категорий (1,7 МБ) в качестве образца данных для работы с
Пример древовидных структур в действии
Следующий скрипт создаст древовидную структуру и сохранит ее в MySQL. Это довольно долго, но это должно дать вам хорошее представление о том, как воспользоваться преимуществами древовидной структуры и достаточно легко адаптироваться под ваши собственные нужды.
Эта первая часть сообщения из 2 частей дает вам сценарий, позволяющий создавать и хранить структуры каталогов. Примечания в нижней части страницы должны помочь вам ознакомиться со сценарием на случай, если у вас возникнут проблемы или вам будет интересно поработать с ним в соответствии с вашими собственными требованиями. 2-й пост содержит базовый графический интерфейс и функции администратора для просмотра и изменения древовидной структуры.
Если я правильно понимайте жаргон (он может быть немного тяжелым) этот скрипт представляет собой "обход дерева предварительного заказа", который может привести к новому способу анализа и экстраполяции ваших данных.
This method avoids recursion, you can fetch breadcrumbs for a category thats 14 levels, 20 levels or even 50 levels deep using one query. In this particular script both the parent and child categories are fetched in one query.
All subcategories are methodically encapsulated within their parent nodes, and each node can give you a calculation of how many subcategories there are without any further querying
Generally, for static and/or large tree structures, this structuring of your categories is advantageous for speed and ease of querying.
The cost is that updates to the tree structure can be expensive, i.e. removing or adding (and sometimes editing) a node in the middle of the tree, which requires altering all records to the 'right side' of the tree to avoid having gaps or collisions in the tree structure. In general, you want to avoid having to update a large tree often, or save the updates for one particular moment where the whole tree can be rebuilt with its updates.
Сохраните и запустите следующий сценарий для создания некоторых примеров данных. Предполагается, что у вас установлен MySQL и уже создана база данных под названием "тест".
<?php
// buildtree.php
mysql_connect('localhost','root','root') or die('Cant connect to MySQL');
mysql_select_db('test') or die('Cant connect to MySQL');
/*
Using the dmozregional.txt file on innvo.com, otherwise you can pass a different file or even an array
Contains around 314,000 categories
Will take about 40 seconds to process, ensure you have enough memory (around 200MB in this case)
and roughly 10x the size of your input file in general cases
*/
$tree = new generate_tree(fopen('dmozregional.txt','r'));
$tree->to_mysql_data();
class generate_tree {
var $cats = array();
var $thiscat = array();
var $depths = array();
var $lftrgt = array();
var $depth = 0;
var $inc = 0;
var $catid = 0;
var $fp1,$fp2;
/*
Run generate_tree once if your dataset is small or memory is not an issue.
*/
public function generate_tree(&$linearcats)
{
$this->depth = 0;
$this->cats = array();
echo "Step 1: Gathering Data: ".date('H:i:s')."\n";
if(is_array($linearcats)) // Run through array
{
foreach($linearcats as $cat)
{
$this->cats[$cat] = array(); // Adding to 2 dimension list of categories with $cat as the key
array_shift($linearcats);
}
}
elseif(is_resource($linearcats))
{
while(!feof($linearcats))
{
if(!trim($cat = trim(fgets($linearcats))))
continue;
$this->cats[$cat] = array(); // Adding to 2 dimension list of categories with $cat as the key
}
}
if(!is_resource($this->fp1)) // 1st Pass, open files
{
$this->fp1 = fopen('/tmp/tree.txt','w');
$this->fp2 = fopen('/tmp/top.txt','w');
}
echo "Step 2: Tree Structure: ".date('H:i:s')."\n";
$this->cats = $this->explodeTree($this->cats);
echo "Step 3: Pre-Order Tree Traversal: ".date('H:i:s')."\n";
$this->mptt($this->cats);
}
/********************************
Function explodeTree with thanks to Kevin van Zonneveld
info: http://kevin.vanzonneveld.net/techblog/article/convert_anything_to_tree_structures_in_php/
Altered from original version but serves largely the same purpose
Example input data is same/similar as example data in the above URL
********************************/
public function explodeTree($array) {
if(!is_array($array) || !count($array))
return array();
$returnArr = array();
foreach ($array as $key => $val)
{
// Get parent parents and the current leaf
$parents = preg_split("'/'",$key,-1,PREG_SPLIT_NO_EMPTY);
$leaf = array_pop($parents);
// Build parent structure
// Might be slow for really deep and large structures
$parentArr = &$returnArr;
foreach($parents as $parent)
{
if(!isset($parentArr[$parent]))
$parentArr[$parent] = array();
elseif(!is_array($parentArr[$parent]))
$parentArr[$parent] = array();
$parentArr = &$parentArr[$parent];
}
// Add the final part to the structure
if(empty($parentArr[$leaf]))
$parentArr[$leaf] = $val;
elseif(is_array($parentArr[$leaf]))
$parentArr[$leaf][] = $val;
}
return $returnArr;
}
/********************************
Function mptt (modified pre-order tree traversal)
Used to recursively walk through the array and provide lft and rgt values (and category depth)
********************************/
public function mptt(&$cats) {
foreach($cats as $catname => $array)
{
$this->depths[$this->depth] = 0;
$this->thiscat[$this->depth] = $catname; // Marking this depth of categories as this category
$imp = implode('/',$this->thiscat); // Full category path
$this->lftrgt[$imp] = array(++$this->inc,++$this->catid); // Assign lft
if(count($array))
{
++$this->depth; // Deeper
$this->mptt($array); // Reiterate
}
fwrite($this->fp1,$this->lftrgt[$imp][0]."\t".(++$this->inc)."\t".count($this->thiscat)."\t".$this->lftrgt[$imp][1]."\t".strtoupper(md5($imp))."\t".$catname."\n"); // $lft $rgt $depth $id $hash $name
if($this->depth == 0)
fwrite($this->fp2,$this->lftrgt[$imp][1]."\n");
unset($this->lftrgt[$imp]);
}
--$this->depth; // Shallower
array_pop($this->thiscat); // Pop this category depth as we're moving up from here
}
/********************************
Function mysql_data
Creates schema, deletes any old data and creates indexes if not already made.
Deletes temporary file data that MySQL uses to load data into tables
********************************/
public function to_mysql_data() {
echo "Step 4: MySQL Schema: ".date('H:i:s')."\n";
// Creating DB Schema and populating with data. Deleting any old data if present
mysql_query('CREATE TABLE IF NOT EXISTS category_tree (
lft mediumint(8) unsigned NOT NULL,
rgt mediumint(8) unsigned NOT NULL,
depth tinyint(3) unsigned NOT NULL,
id mediumint(8) unsigned NOT NULL,
hash binary(16) NOT NULL,
name varbinary(255) NOT NULL)
ENGINE=InnoDB;')
or die(mysql_error());
mysql_query('TRUNCATE TABLE category_tree')
or die(mysql_error());
mysql_query('LOAD DATA INFILE \'/tmp/tree.txt\' INTO TABLE category_tree FIELDS TERMINATED BY \'\t\' (lft,rgt,depth,id,@hash,name) SET hash = UNHEX(@hash)')
or die(mysql_error());
mysql_query('INSERT INTO category_tree (lft,rgt,depth,id) SELECT 0,MAX(rgt)+1,0,0 FROM category_tree') or die(mysql_error());
mysql_query('CREATE TABLE IF NOT EXISTS category_top (id MEDIUMINT(8) unsigned NOT NULL,PRIMARY KEY (id)) ENGINE=MyISAM')
or die(mysql_error());
mysql_query('TRUNCATE TABLE category_top')
or die(mysql_error());
mysql_query('LOAD DATA INFILE \'/tmp/top.txt\' INTO TABLE category_top FIELDS TERMINATED BY \'\t\'')
or die(mysql_error());
// Delete temporary data
unlink('/tmp/tree.txt');
unlink('/tmp/top.txt');
echo "Step 5: MySQL Indexes: ".date('H:i:s')."\n";
// Adding indexes for SELECT speed. Script will die appropriately here if you have already created the indexes
mysql_query('ALTER TABLE category_tree ADD PRIMARY KEY (lft,rgt,depth);') or die('I1 '.mysql_error());
mysql_query('ALTER TABLE category_tree ADD UNIQUE (id);') or die('I2 '.mysql_error());
mysql_query('ALTER TABLE category_tree ADD UNIQUE (hash);') or die('I3 '.mysql_error());
}
}
?>
Обзор сценария
Lines 4-5: Connect to MySQL or terminate script
Line 13: Generate the tree structure. You can call this more than once if you have a large dataset. One method would be to call generate_tree() for every top level category you have so that tree sizes are limited to them.
Line 14: $tree->to_mysql_data() is called at the end to write data to MySQL, after all the following events have occurred
Lines 28-61: Function generate_tree, invoked when the class is initiated.
- Lines 33-49: Loads the data you pass into an array, with values situated in the array keys. You can pass an array to this function or a file resource. For files, ensure there is one record per line.
- Lines 52-55: On first invocation, a couple of temporary files are created for storing data deriving from the tree structure
- Line 58: Calls explodeTree() which converts the array to a multi-dimensional tree array
- Line 60: mptt() to create the lft, rgt and depth values in order to use our tree in MySQL. Data is written to temporary files that are then used by MySQL to populate the tables.
Если я правильно вас понимаю, у вас классическая структура логической таблицы "многие ко многим" с самореферентными ссылками. Это легко решается путем создания трех таблиц: одна для представления ваших "узлов", другая для представления "ассоциаций" между узлами" между родителями и детьми", а другая для представления отношений между братьями и сестрами. Я не уверен, что вам нужно напрямую представлять отношения между братьями и сестрами, поскольку они могут быть выведены из отношений между родителями и детьми. Однако, поскольку вы не оказали "зеленые" линии отношений для всех братьев и сестер, я предполагаю, что это какие-то "особые" отношения. Таблицы/столбцы могут быть смоделированы следующим образом:
Узел
- идентификатор узла (pk)
- . . .
Карта узлов
- идентификатор родителя (fk для node.node_id)
- идентификатор дочернего элемента (fk для node.node_id)
Node_sibling_map
- идентификатор узла (fk к узлу.идентификатор узла)
- идентификатор родного брата (fk для node.node_id)
Для заполнения таблицы вы описали в этой модели, вам нужно будет выполнить следующее. (кавычки опущены).
- вставить в узел (node_id) значения (A);
- вставить в узел (node_id) значения (B);
- вставить в узел (node_id) значения (C);
- вставить в узел (node_id) значения (A1);
- вставить в узел (идентификатор узла) значения (A2);
- вставить в узел (node_id) значения (B1);
- вставить в узел (node_id) значения (B2);
- вставить в узел (node_id) значения (B3);
- вставить в значения узла (node_id) (A2B1);
- вставить в узел (node_id) значения (CB3);
- вставить в узел (node_id) значения (A2B1B2);
- вставить в узел (идентификатор узла) значения(X);
- вставить в узел (идентификатор узла) значения (Y);
- вставить в узел (node_id) значения (Z);
- вставить в node_map (parent_id, child_id) значения (A,A1);
- вставить в node_map (parent_id, child_id) значения (A,A2);
- вставить в node_map (parent_id, child_id) значения (B,B1);
- вставить в значения node_map (parent_id, child_id) (B, B2);
- вставить в node_map (parent_id, child_id) значения (B, B3);
- вставить в node_map (parent_id, child_id) значения (C,CB3);
- вставить в node_map (parent_id, child_id) значения (A2,A2B1);
- вставить в node_map (parent_id, child_id) значения (B1,A2B1);
- вставить в node_map (parent_id, child_id) значения (B2,A2B1B2);
- вставить в node_map (parent_id, child_id) значения (B3, CB3);
- вставить в карту узлов (parent_id, child_id) значения (C, CB3);
- вставить в node_map (идентификатор родителя, идентификатор ребенка) значения (A2B1B2,X);
- вставить в node_map (идентификатор родителя, идентификатор ребенка) значения (A2B1B2, Y);
- вставить в node_map (parent_id, child_id) значения (A2B1B2, Z);
- вставить в node_sibling_map (node_id, sibling_id) значения (B1, B2);
- вставить в node_sibling_map (node_id, sibling_id) значения (B2, B3);
- вставить в node_sibling_map (идентификатор узла, идентификатор сестры) значения (X,Y);
- вставить в значения node_sibling_map (идентификатор узла, идентификатор брата и сестры) (Y,Z);
Это довольно сложная проблема, с которой вы имеете дело. Возможно, стоит проверить следующие статьи:
Http://www.codeproject.com/Articles/22824/A-Model-to-Represent-Directed-Acyclic-Graphs-DAG-o http://www.freepatentsonline.com/6633886.html