Каков наилучший способ в PHP прочитать последние строки из файла?
В моем PHP-приложении мне нужно прочитать несколько строк, начиная с конца
многих файлов (в основном журналов). Иногда мне нужен только последний, иногда мне нужны
десятки или сотни. В принципе, я хочу что-то столь же гибкое, как команда Unix tail
.
Здесь есть вопросы о том, как получить единственную последнюю строку из файла (но Мне нужно N строк), и были даны различные решения. Я не уверен, какой из них лучший и какой работает лучше.
4 answers
Обзор методов
В поисках в Интернете я наткнулся на разные решения. Я могу сгруппировать их в три подхода:
-
наивные те, которые используют
file()функцию PHP; -
обман тех, кто выполняет команду
tailв системе; -
могучие те, которые радостно прыгают вокруг открытого файла, используя
fseek().
В итоге я выбрал (или написал) пять решений, наивное одно, мошенничество один и три могущественных .
- Самый краткий наивное решение, использование встроенных функций массива.
- В единственное возможное решение, основанное на
tailкоманда, который немного большая проблема: он не работает, еслиtailнет в наличии, как на не Unix (Windows) или на ограниченных условиях, которые не позволяют системе функции. - Решение, в котором отдельные байты считываются с конца из файла , в котором выполняется поиск (и подсчет) символов новой строки, найдено здесь.
- Найдено многобайтовое буферизованное решение, оптимизированное для больших файлов здесь.
- Немного измененная версия решения #4 в котором длина буфера является динамической, определяется в соответствии с количеством строк для извлечения.
Все решения работают . В том смысле, что они возвращают ожидаемый результат из любого файла и для любого количества строк, которые мы запрашиваем (за исключением решения № 1, которое может нарушить ограничения памяти PHP в случае больших файлов, ничего не возвращая). Но какой из них лучше?
Тесты производительности
Чтобы ответить на этот вопрос, я провожу тесты. Вот как это делается, не так ли?
Я подготовил образец файла объемом 100 КБ, объединяющий различные файлы, найденные в
моем каталоге /var/log. Затем я написал PHP-скрипт, который использует каждое из
пяти решений для извлечения 1, 2, .., 10, 20, ... 100, 200, ..., 1000 строки
из конца файла. Каждый отдельный тест повторяется десять раз (это что
-то вроде 5 × 28 × 10 = 1400 тесты), измеряющий среднее затраченное
время в микросекундах.
Я запускаю скрипт на своей локальной машине разработки (Xubuntu 12.04, PHP 5.3.10, двухъядерный процессор 2,70 ГГц, 2 ГБ оперативной памяти), используя интерпретатор командной строки PHP . Вот результаты:
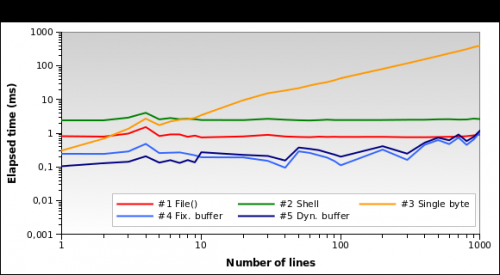
Решения № 1 и № 2 кажутся хуже те. Решение № 3 хорошо только тогда, когда нам нужно прочитать несколько строк. Решения № 4 и № 5 кажутся лучшими. Обратите внимание, как динамический размер буфера может оптимизировать алгоритм: время выполнения немного меньше для нескольких строк из-за уменьшенного буфера.
Давайте попробуем с файлом большего размера. Что делать, если нам нужно прочитать 10 МБ файл журнала?
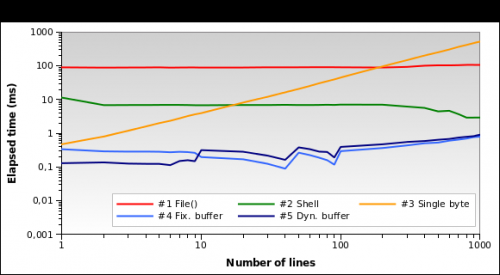
Теперь решение № 1 намного хуже: на самом деле загрузка всего файла объемом 10 МБ в память не является большой идея. Я также провожу тесты с файлами размером 1 МБ и 100 МБ, и это практически та же ситуация.
А для крошечных файлов журналов? Это график для файла размером 10 КБ:
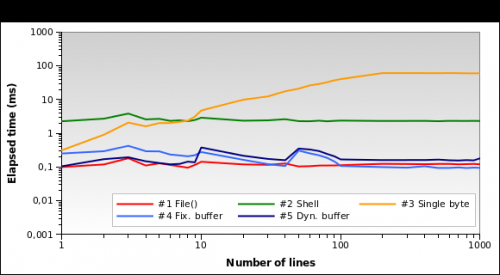
Решение № 1 сейчас самое лучшее! Загрузка 10 КБ в память не имеет большого значения для PHP. Также # 4 и #5 работают хорошо. Однако это крайний случай: журнал размером 10 КБ означает что-то вроде 150/200 строк...
Вы можете скачать все мои тестовые файлы, источники и результаты здесь.
Заключительные мысли
Решение №5 настоятельно рекомендуется для общего случая использования: отлично работает с файлами любого размера и особенно хорошо работает при чтении нескольких строк.
Избегайте решение #1 если вам нужно прочитать файлы размером более 10 КБ.
Решение #2 и #3 не являются лучшими для каждого теста, который я провожу: # 2 никогда не выполняется менее чем за 2 мс, и #3 - это сильно зависит от количества строк, которые вы задаете (довольно хорошо работает только с 1 или 2 строками).
Это измененная версия, которая также может пропускать последние строки:
/**
* Modified version of http://www.geekality.net/2011/05/28/php-tail-tackling-large-files/ and of https://gist.github.com/lorenzos/1711e81a9162320fde20
* @author Kinga the Witch (Trans-dating.com), Torleif Berger, Lorenzo Stanco
* @link http://stackoverflow.com/a/15025877/995958
* @license http://creativecommons.org/licenses/by/3.0/
*/
function tailWithSkip($filepath, $lines = 1, $skip = 0, $adaptive = true)
{
// Open file
$f = @fopen($filepath, "rb");
if (@flock($f, LOCK_SH) === false) return false;
if ($f === false) return false;
if (!$adaptive) $buffer = 4096;
else {
// Sets buffer size, according to the number of lines to retrieve.
// This gives a performance boost when reading a few lines from the file.
$max=max($lines, $skip);
$buffer = ($max < 2 ? 64 : ($max < 10 ? 512 : 4096));
}
// Jump to last character
fseek($f, -1, SEEK_END);
// Read it and adjust line number if necessary
// (Otherwise the result would be wrong if file doesn't end with a blank line)
if (fread($f, 1) == "\n") {
if ($skip > 0) { $skip++; $lines--; }
} else {
$lines--;
}
// Start reading
$output = '';
$chunk = '';
// While we would like more
while (ftell($f) > 0 && $lines >= 0) {
// Figure out how far back we should jump
$seek = min(ftell($f), $buffer);
// Do the jump (backwards, relative to where we are)
fseek($f, -$seek, SEEK_CUR);
// Read a chunk
$chunk = fread($f, $seek);
// Calculate chunk parameters
$count = substr_count($chunk, "\n");
$strlen = mb_strlen($chunk, '8bit');
// Move the file pointer
fseek($f, -$strlen, SEEK_CUR);
if ($skip > 0) { // There are some lines to skip
if ($skip > $count) { $skip -= $count; $chunk=''; } // Chunk contains less new line symbols than
else {
$pos = 0;
while ($skip > 0) {
if ($pos > 0) $offset = $pos - $strlen - 1; // Calculate the offset - NEGATIVE position of last new line symbol
else $offset=0; // First search (without offset)
$pos = strrpos($chunk, "\n", $offset); // Search for last (including offset) new line symbol
if ($pos !== false) $skip--; // Found new line symbol - skip the line
else break; // "else break;" - Protection against infinite loop (just in case)
}
$chunk=substr($chunk, 0, $pos); // Truncated chunk
$count=substr_count($chunk, "\n"); // Count new line symbols in truncated chunk
}
}
if (strlen($chunk) > 0) {
// Add chunk to the output
$output = $chunk . $output;
// Decrease our line counter
$lines -= $count;
}
}
// While we have too many lines
// (Because of buffer size we might have read too many)
while ($lines++ < 0) {
// Find first newline and remove all text before that
$output = substr($output, strpos($output, "\n") + 1);
}
// Close file and return
@flock($f, LOCK_UN);
fclose($f);
return trim($output);
}
Это также сработало бы:
$file = new SplFileObject("/path/to/file");
$file->seek(PHP_INT_MAX); // cheap trick to seek to EoF
$total_lines = $file->key(); // last line number
// output the last twenty lines
$reader = new LimitIterator($file, $total_lines - 20);
foreach ($reader as $line) {
echo $line; // includes newlines
}
Или без LimitIterator:
$file = new SplFileObject($filepath);
$file->seek(PHP_INT_MAX);
$total_lines = $file->key();
$file->seek($total_lines - 20);
while (!$file->eof()) {
echo $file->current();
$file->next();
}
К сожалению, ваш тестовый набор сегментируется на моей машине, поэтому я не могу сказать, как он работает.
Еще одна функция, вы можете использовать регулярные выражения для разделения элементов. Использование
$last_rows_array = file_get_tail('logfile.log', 100, array(
'regex' => true, // use regex
'separator' => '#\n{2,}#', // separator: at least two newlines
'typical_item_size' => 200, // line length
));
Функция:
// public domain
function file_get_tail( $file, $requested_num = 100, $args = array() ){
// default arg values
$regex = true;
$separator = null;
$typical_item_size = 100; // estimated size
$more_size_mul = 1.01; // +1%
$max_more_size = 4000;
extract( $args );
if( $separator === null ) $separator = $regex ? '#\n+#' : "\n";
if( is_string( $file )) $f = fopen( $file, 'rb');
else if( is_resource( $file ) && in_array( get_resource_type( $file ), array('file', 'stream'), true ))
$f = $file;
else throw new \Exception( __METHOD__.': file must be either filename or a file or stream resource');
// get file size
fseek( $f, 0, SEEK_END );
$fsize = ftell( $f );
$fpos = $fsize;
$bytes_read = 0;
$all_items = array(); // array of array
$all_item_num = 0;
$remaining_num = $requested_num;
$last_junk = '';
while( true ){
// calc size and position of next chunk to read
$size = $remaining_num * $typical_item_size - strlen( $last_junk );
// reading a bit more can't hurt
$size += (int)min( $size * $more_size_mul, $max_more_size );
if( $size < 1 ) $size = 1;
// set and fix read position
$fpos = $fpos - $size;
if( $fpos < 0 ){
$size -= -$fpos;
$fpos = 0;
}
// read chunk + add junk from prev iteration
fseek( $f, $fpos, SEEK_SET );
$chunk = fread( $f, $size );
if( strlen( $chunk ) !== $size ) throw new \Exception( __METHOD__.": read error?");
$bytes_read += strlen( $chunk );
$chunk .= $last_junk;
// chunk -> items, with at least one element
$items = $regex ? preg_split( $separator, $chunk ) : explode( $separator, $chunk );
// first item is probably cut in half, use it in next iteration ("junk") instead
// also skip very first '' item
if( $fpos > 0 || $items[0] === ''){
$last_junk = $items[0];
unset( $items[0] );
} // … else noop, because this is the last iteration
// ignore last empty item. end( empty [] ) === false
if( end( $items ) === '') array_pop( $items );
// if we got items, push them
$num = count( $items );
if( $num > 0 ){
$remaining_num -= $num;
// if we read too much, use only needed items
if( $remaining_num < 0 ) $items = array_slice( $items, - $remaining_num );
// don't fix $remaining_num, we will exit anyway
$all_items[] = array_reverse( $items );
$all_item_num += $num;
}
// are we ready?
if( $fpos === 0 || $remaining_num <= 0 ) break;
// calculate a better estimate
if( $all_item_num > 0 ) $typical_item_size = (int)max( 1, round( $bytes_read / $all_item_num ));
}
fclose( $f );
//tr( $all_items );
return call_user_func_array('array_merge', $all_items );
}